Data preparation
After the raw data processing, peak tables for positive and negative mode have been generated.
Next, we need to get the peak table and sample information and organize them as mass_dataset class objects.
library(tidymass)
#> Registered S3 method overwritten by 'Hmisc':
#> method from
#> vcov.default fit.models
#> ── Attaching packages ──────────────────────────────────────── tidymass 1.0.9 ──
#> ✔ massdataset 1.0.34 ✔ metid 1.2.33
#> ✔ massprocesser 1.0.10 ✔ masstools 1.0.13
#> ✔ masscleaner 1.0.12 ✔ dplyr 1.1.4
#> ✔ massqc 1.0.7 ✔ ggplot2 3.5.1
#> ✔ massstat 1.0.6 ✔ magrittr 2.0.3
#> ✔ metpath 1.0.8
library(tidyverse)
#> ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
#> ✔ forcats 1.0.0 ✔ readr 2.1.5
#> ✔ lubridate 1.9.3 ✔ stringr 1.5.1
#> ✔ purrr 1.0.2 ✔ tibble 3.2.1
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ xcms::collect() masks dplyr::collect()
#> ✖ MSnbase::combine() masks Biobase::combine(), BiocGenerics::combine(), dplyr::combine()
#> ✖ tidyr::expand() masks S4Vectors::expand()
#> ✖ tidyr::extract() masks magrittr::extract()
#> ✖ metid::filter() masks metpath::filter(), dplyr::filter(), massdataset::filter(), stats::filter()
#> ✖ S4Vectors::first() masks dplyr::first()
#> ✖ xcms::groups() masks dplyr::groups()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ purrr::map() masks mixOmics::map()
#> ✖ BiocGenerics::Position() masks ggplot2::Position(), base::Position()
#> ✖ purrr::reduce() masks MSnbase::reduce()
#> ✖ S4Vectors::rename() masks dplyr::rename(), massdataset::rename()
#> ✖ lubridate::second() masks S4Vectors::second()
#> ✖ lubridate::second<-() masks S4Vectors::second<-()
#> ✖ MASS::select() masks dplyr::select(), massdataset::select()
#> ✖ purrr::set_names() masks magrittr::set_names()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Positive mode
Load object.
load("mzxml_ms1_data/POS/Result/object")
object_pos <- object
object_pos
#> --------------------
#> massdataset version: 0.99.8
#> --------------------
#> 1.expression_data:[ 10149 x 259 data.frame]
#> 2.sample_info:[ 259 x 4 data.frame]
#> 259 samples:sample_06 sample_103 sample_11 ... sample_QC_38 sample_QC_39
#> 3.variable_info:[ 10149 x 3 data.frame]
#> 10149 variables:M70T73_POS M70T53_POS M70T183_POS ... M923T55_POS M992T641_POS
#> 4.sample_info_note:[ 4 x 2 data.frame]
#> 5.variable_info_note:[ 3 x 2 data.frame]
#> 6.ms2_data:[ 0 variables x 0 MS2 spectra]
#> --------------------
#> Processing information
#> 2 processings in total
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-02-23 08:37:06
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-02-23 08:36:42
Read sample information.
sample_info_pos <- readr::read_csv("sample_info/sample_info_pos.csv")
#> Rows: 259 Columns: 6
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (4): sample_id, class, subject_id, group
#> dbl (2): injection.order, batch
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
head(sample_info_pos)
#> # A tibble: 6 × 6
#> sample_id injection.order class batch subject_id group
#> <chr> <dbl> <chr> <dbl> <chr> <chr>
#> 1 sample_QC_01 1 QC 1 <NA> QC
#> 2 sample_01 2 Subject 1 subject_474 Control
#> 3 sample_02 3 Subject 1 subject_431 Control
#> 4 sample_06 4 Subject 1 subject_414 Case
#> 5 sample_07 5 Subject 1 subject_830 Control
#> 6 sample_11 6 Subject 1 subject_125 Case
Add sample_info_pos to object_pos
object_pos %>%
extract_sample_info() %>%
head()
#> sample_id group class injection.order
#> 1 sample_06 Case Subject 1
#> 2 sample_103 Case Subject 2
#> 3 sample_11 Case Subject 3
#> 4 sample_112 Case Subject 4
#> 5 sample_117 Case Subject 5
#> 6 sample_12 Case Subject 6
object_pos <-
object_pos %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::select(-c("group", "class", "injection.order"))
object_pos =
object_pos %>%
activate_mass_dataset(what = "sample_info") %>%
left_join(sample_info_pos,
by = "sample_id")
object_pos %>%
extract_sample_info() %>%
head()
#> sample_id injection.order class batch subject_id group
#> 1 sample_06 4 Subject 1 subject_414 Case
#> 2 sample_103 71 Subject 1 subject_330 Case
#> 3 sample_11 6 Subject 1 subject_125 Case
#> 4 sample_112 78 Subject 1 subject_295 Case
#> 5 sample_117 80 Subject 1 subject_793 Case
#> 6 sample_12 8 Subject 1 subject_387 Case
Save the object_pos in a new folder named as data_cleaning.
dir.create("data_cleaning/POS", showWarnings = FALSE, recursive = TRUE)
save(object_pos, file = "data_cleaning/POS/object_pos")
object_pos
#> --------------------
#> massdataset version: 0.99.8
#> --------------------
#> 1.expression_data:[ 10149 x 259 data.frame]
#> 2.sample_info:[ 259 x 6 data.frame]
#> 259 samples:sample_06 sample_103 sample_11 ... sample_QC_38 sample_QC_39
#> 3.variable_info:[ 10149 x 3 data.frame]
#> 10149 variables:M70T73_POS M70T53_POS M70T183_POS ... M923T55_POS M992T641_POS
#> 4.sample_info_note:[ 6 x 2 data.frame]
#> 5.variable_info_note:[ 3 x 2 data.frame]
#> 6.ms2_data:[ 0 variables x 0 MS2 spectra]
#> --------------------
#> Processing information
#> 2 processings in total
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-02-23 08:37:06
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-02-23 08:36:42
dim(object_pos)
#> variables samples
#> 10149 259
object_pos %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::count(class)
#> class n
#> 1 QC 39
#> 2 Subject 220
object_pos %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::count(group)
#> group n
#> 1 Case 110
#> 2 Control 110
#> 3 QC 39
object_pos %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::count(batch)
#> batch n
#> 1 1 112
#> 2 2 147
So for positive mode, we have 259 samples and 10,149 variables. 220 subject samples and 39 QC samples. 110 control samples and 110 case samples. Two batches in total, 112 samples in batch 1 and 147 in batch 2.
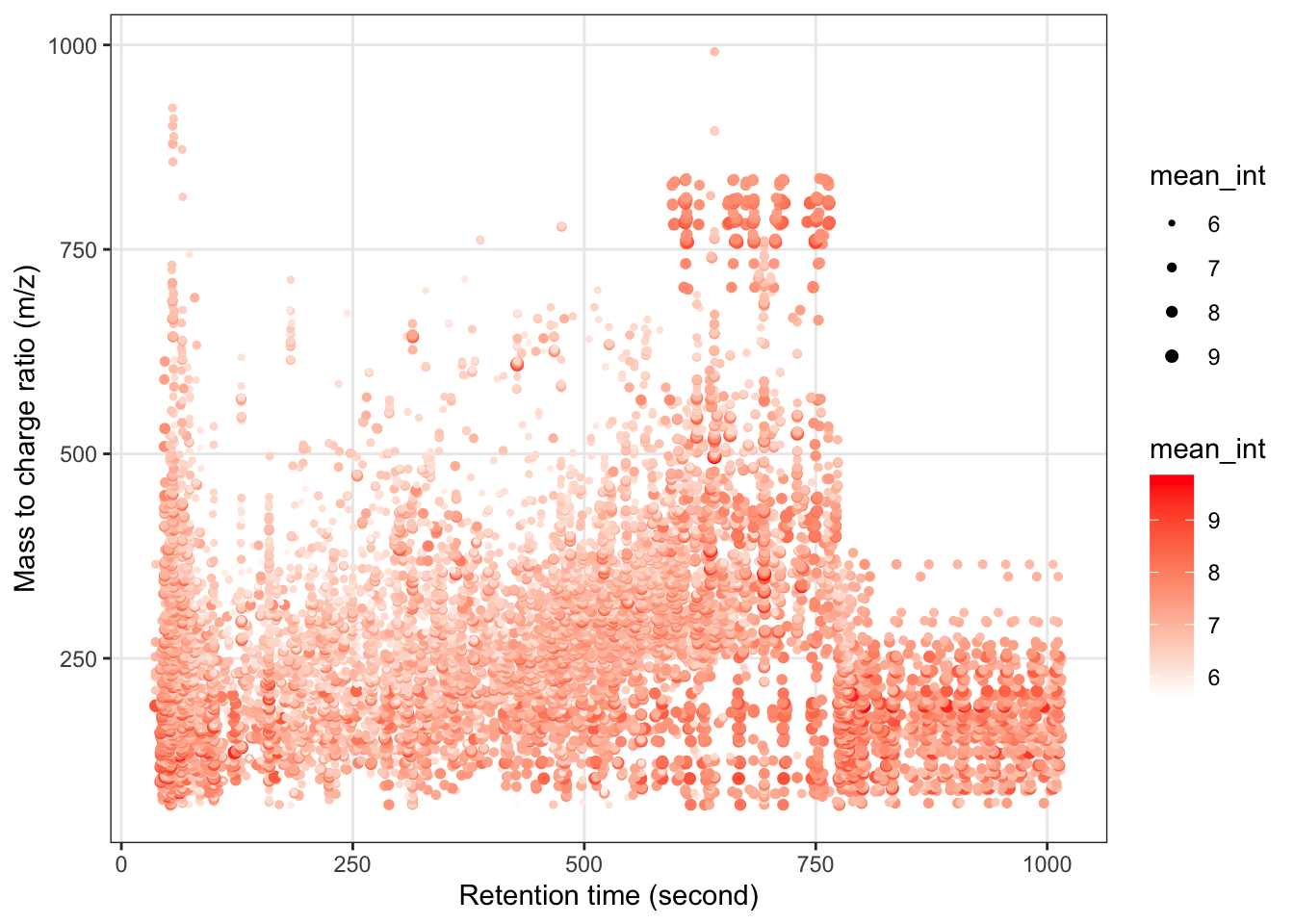
Next, we can get the peak distributation plot of positive mode.
object_pos %>%
`+`(1) %>%
log(10) %>%
show_mz_rt_plot() +
scale_size_continuous(range = c(0.01, 2))
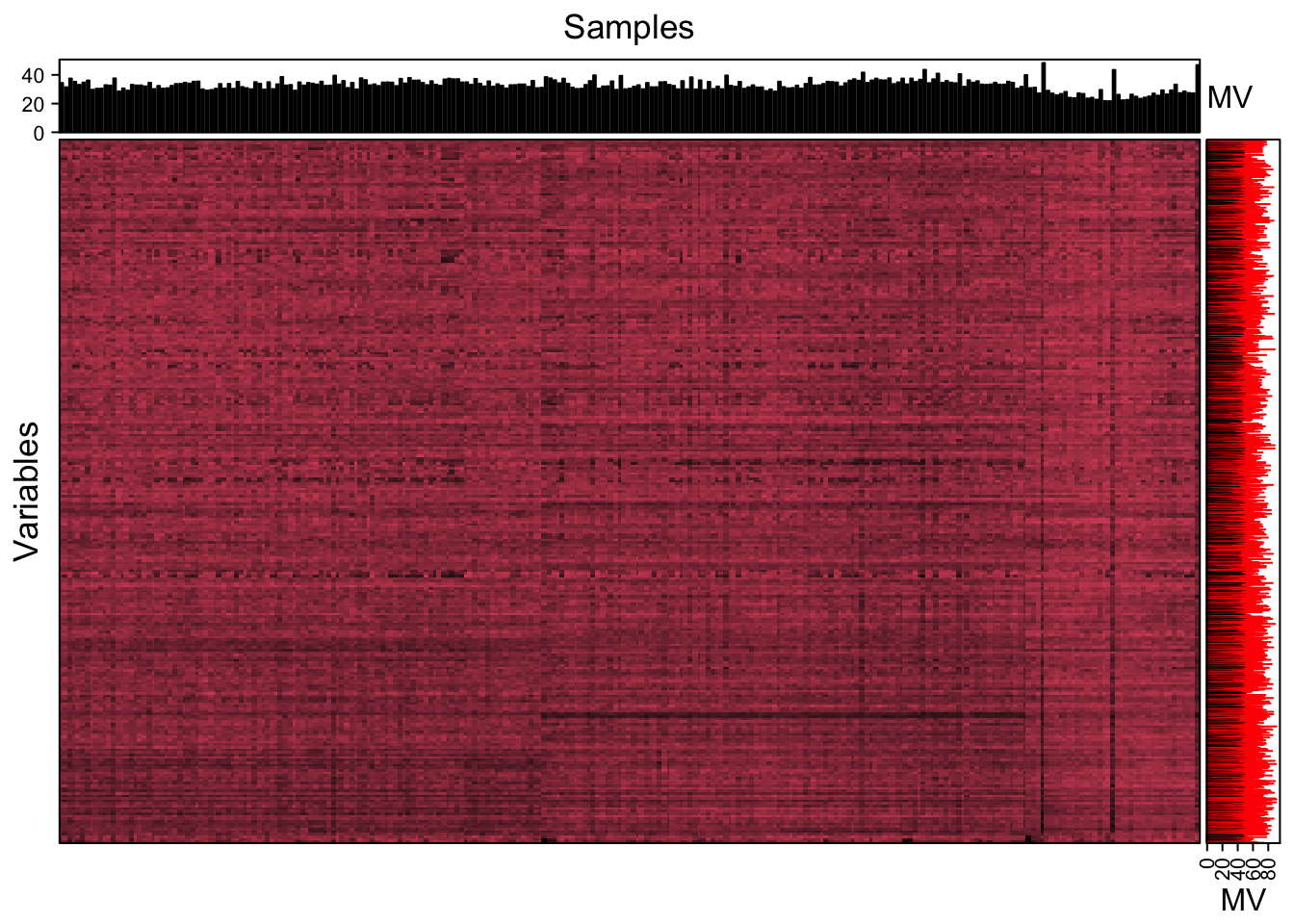
We can explore the missing values (mvs) in positive mode data.
get_mv_number(object = object_pos)
#> [1] 785821
785,821 mvs in total.
get_mv_number(object = object_pos, by = "sample") %>%
head()
#> sample_06 sample_103 sample_11 sample_112 sample_117 sample_12
#> 4016 2711 4063 2981 2919 3844
Missing value number in each sample.
get_mv_number(object = object_pos, by = "variable") %>%
head()
#> M70T73_POS M70T53_POS M70T183_POS M70T527_POS M71T695_POS M71T183_POS
#> 129 16 155 54 133 169
Missing value number in each variable.
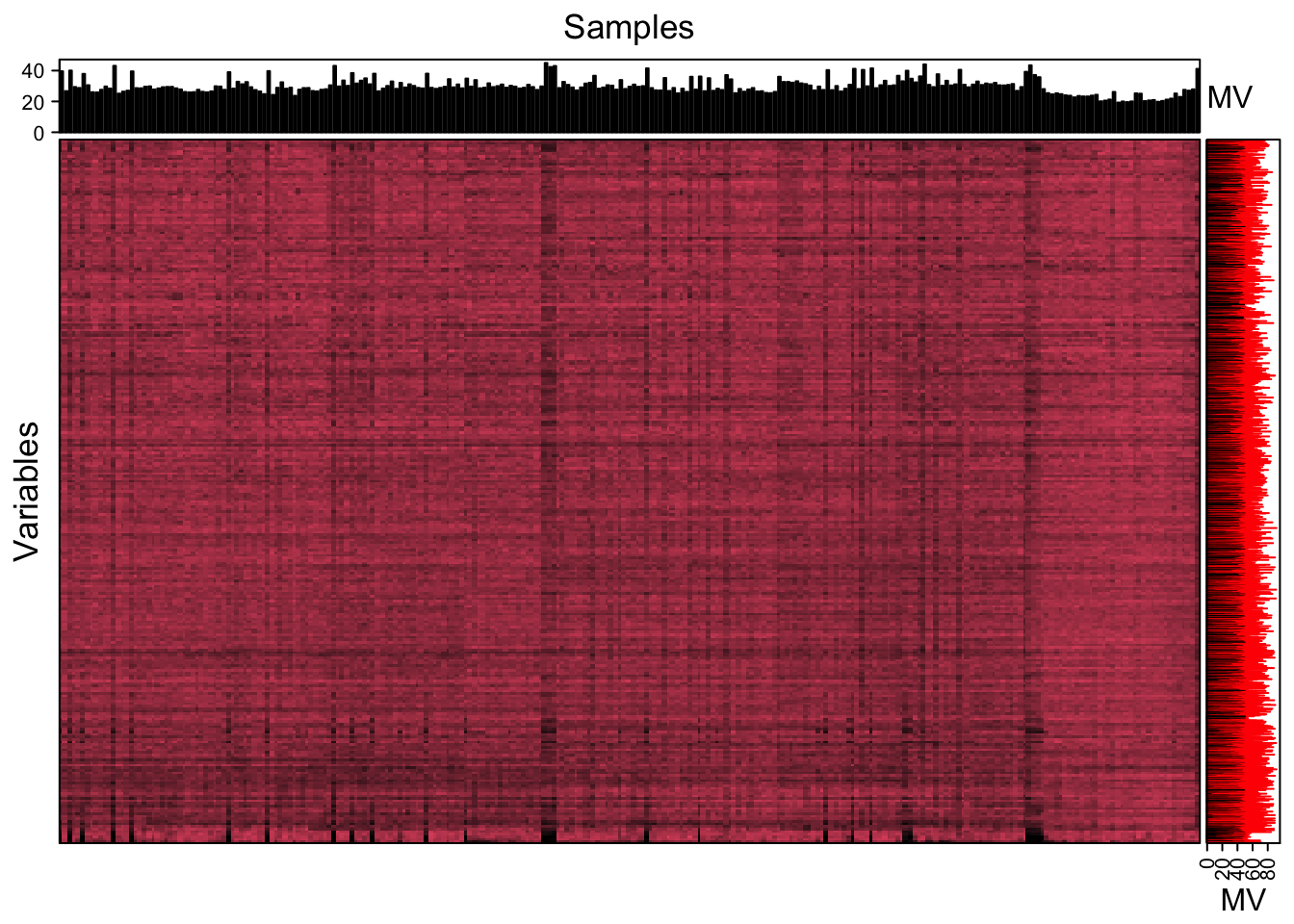
We can use the figure to show the missing value information.
show_missing_values(object = object_pos, show_column_names = FALSE, percentage = TRUE)
Show the mvs in samples.
show_sample_missing_values(object = object_pos, percentage = TRUE)

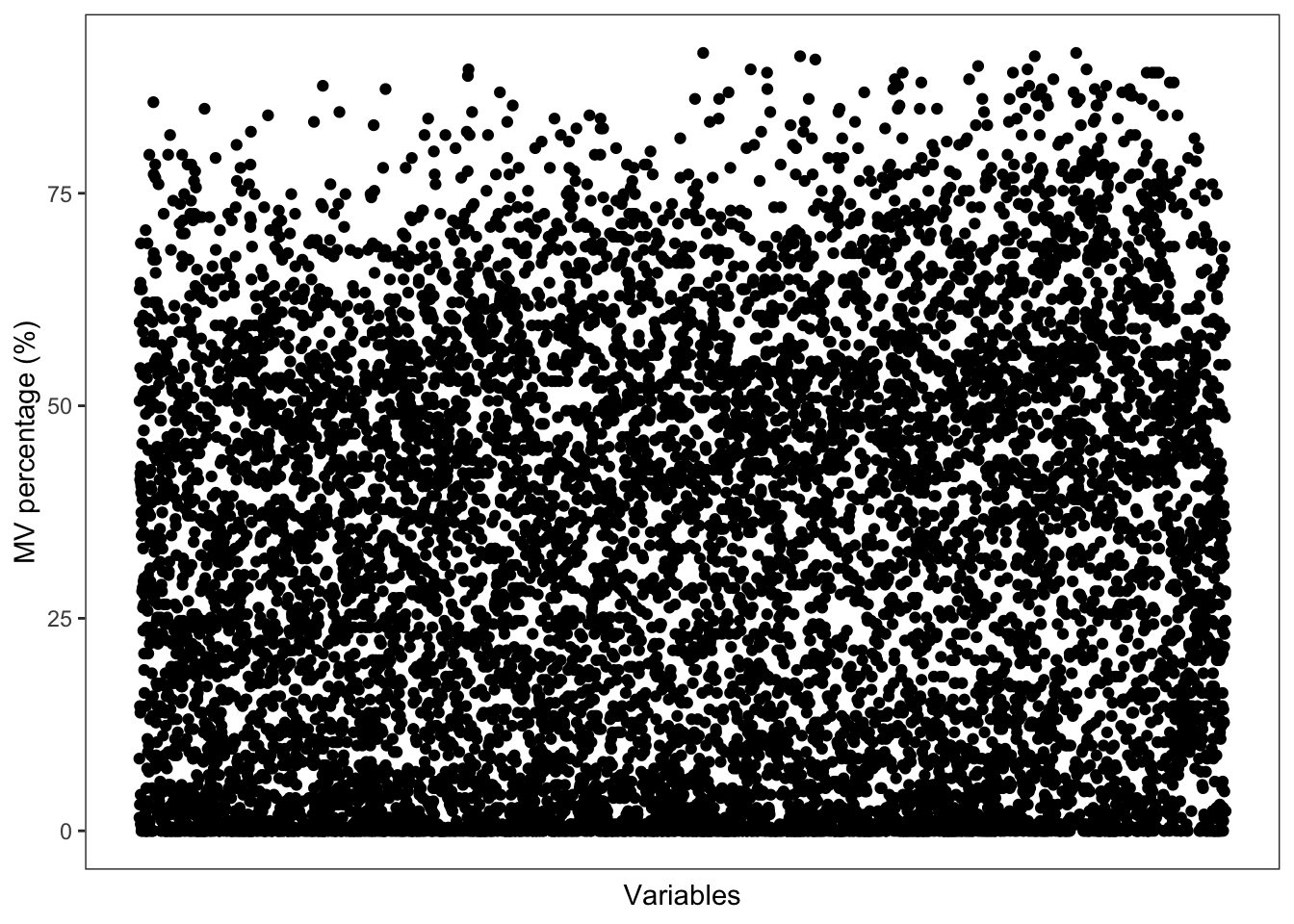
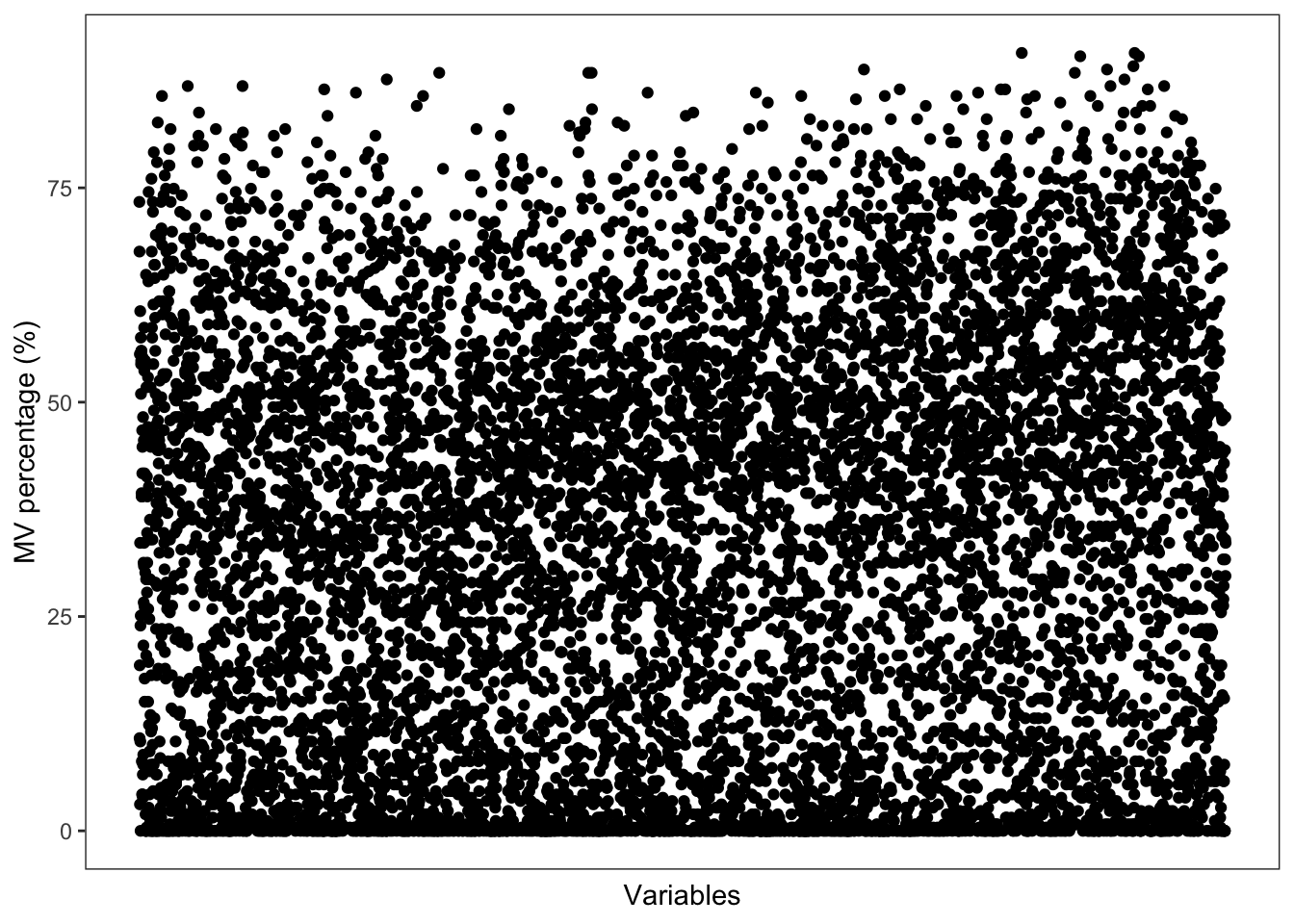
Show the mvs in variables
show_variable_missing_values(
object = object_pos,
percentage = TRUE,
show_x_text = FALSE,
show_x_ticks = FALSE
) +
scale_size_continuous(range = c(0.01, 1))
Negative mode
Load object.
load("mzxml_ms1_data/NEG/Result/object")
object_neg <- object
object_neg
#> --------------------
#> massdataset version: 0.99.8
#> --------------------
#> 1.expression_data:[ 8804 x 259 data.frame]
#> 2.sample_info:[ 259 x 4 data.frame]
#> 259 samples:sample_06 sample_103 sample_11 ... sample_QC_38 sample_QC_39
#> 3.variable_info:[ 8804 x 3 data.frame]
#> 8804 variables:M70T712_NEG M70T527_NEG M70T587_NEG ... M941T65_NEG M948T641_NEG
#> 4.sample_info_note:[ 4 x 2 data.frame]
#> 5.variable_info_note:[ 3 x 2 data.frame]
#> 6.ms2_data:[ 0 variables x 0 MS2 spectra]
#> --------------------
#> Processing information
#> 2 processings in total
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-02-23 08:38:19
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-02-23 08:38:02
Read sample information.
sample_info_neg <-
readr::read_csv("sample_info/sample_info_neg.csv")
#> Rows: 259 Columns: 6
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (4): sample_id, class, subject_id, group
#> dbl (2): injection.order, batch
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
head(sample_info_neg)
#> # A tibble: 6 × 6
#> sample_id injection.order class batch subject_id group
#> <chr> <dbl> <chr> <dbl> <chr> <chr>
#> 1 sample_QC_01 1 QC 1 <NA> QC
#> 2 sample_01 2 Subject 1 subject_474 Control
#> 3 sample_02 3 Subject 1 subject_431 Control
#> 4 sample_06 4 Subject 1 subject_414 Case
#> 5 sample_07 5 Subject 1 subject_830 Control
#> 6 sample_11 6 Subject 1 subject_125 Case
Add sample_info_neg to object_neg
object_neg %>%
extract_sample_info() %>%
head()
#> sample_id group class injection.order
#> 1 sample_06 Case Subject 1
#> 2 sample_103 Case Subject 2
#> 3 sample_11 Case Subject 3
#> 4 sample_112 Case Subject 4
#> 5 sample_117 Case Subject 5
#> 6 sample_12 Case Subject 6
object_neg <-
object_neg %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::select(-c("group", "class", "injection.order"))
object_neg <-
object_neg %>%
activate_mass_dataset(what = "sample_info") %>%
left_join(sample_info_neg,
by = "sample_id")
object_neg %>%
extract_sample_info() %>%
head()
#> sample_id injection.order class batch subject_id group
#> 1 sample_06 4 Subject 1 subject_414 Case
#> 2 sample_103 71 Subject 1 subject_330 Case
#> 3 sample_11 6 Subject 1 subject_125 Case
#> 4 sample_112 78 Subject 1 subject_295 Case
#> 5 sample_117 80 Subject 1 subject_793 Case
#> 6 sample_12 8 Subject 1 subject_387 Case
Save the object_neg in a new folder named as data_cleaning.
dir.create("data_cleaning/NEG", showWarnings = FALSE, recursive = TRUE)
save(object_neg, file = "data_cleaning/NEG/object_neg")
object_neg
#> --------------------
#> massdataset version: 0.99.8
#> --------------------
#> 1.expression_data:[ 8804 x 259 data.frame]
#> 2.sample_info:[ 259 x 6 data.frame]
#> 259 samples:sample_06 sample_103 sample_11 ... sample_QC_38 sample_QC_39
#> 3.variable_info:[ 8804 x 3 data.frame]
#> 8804 variables:M70T712_NEG M70T527_NEG M70T587_NEG ... M941T65_NEG M948T641_NEG
#> 4.sample_info_note:[ 6 x 2 data.frame]
#> 5.variable_info_note:[ 3 x 2 data.frame]
#> 6.ms2_data:[ 0 variables x 0 MS2 spectra]
#> --------------------
#> Processing information
#> 2 processings in total
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2022-02-23 08:38:19
#> process_data ----------
#> Package Function.used Time
#> 1 massprocesser process_data 2022-02-23 08:38:02
dim(object_neg)
#> variables samples
#> 8804 259
object_neg %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::count(class)
#> class n
#> 1 QC 39
#> 2 Subject 220
object_neg %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::count(group)
#> group n
#> 1 Case 110
#> 2 Control 110
#> 3 QC 39
object_neg %>%
activate_mass_dataset(what = "sample_info") %>%
dplyr::count(batch)
#> batch n
#> 1 1 86
#> 2 2 173
So for negative mode, we have 259 samples and 8,804 variables. 220 subject samples and 39 QC samples. 110 control samples and 110 case samples. Two batches in total, 112 samples in batch 1 and 147 in batch 2.
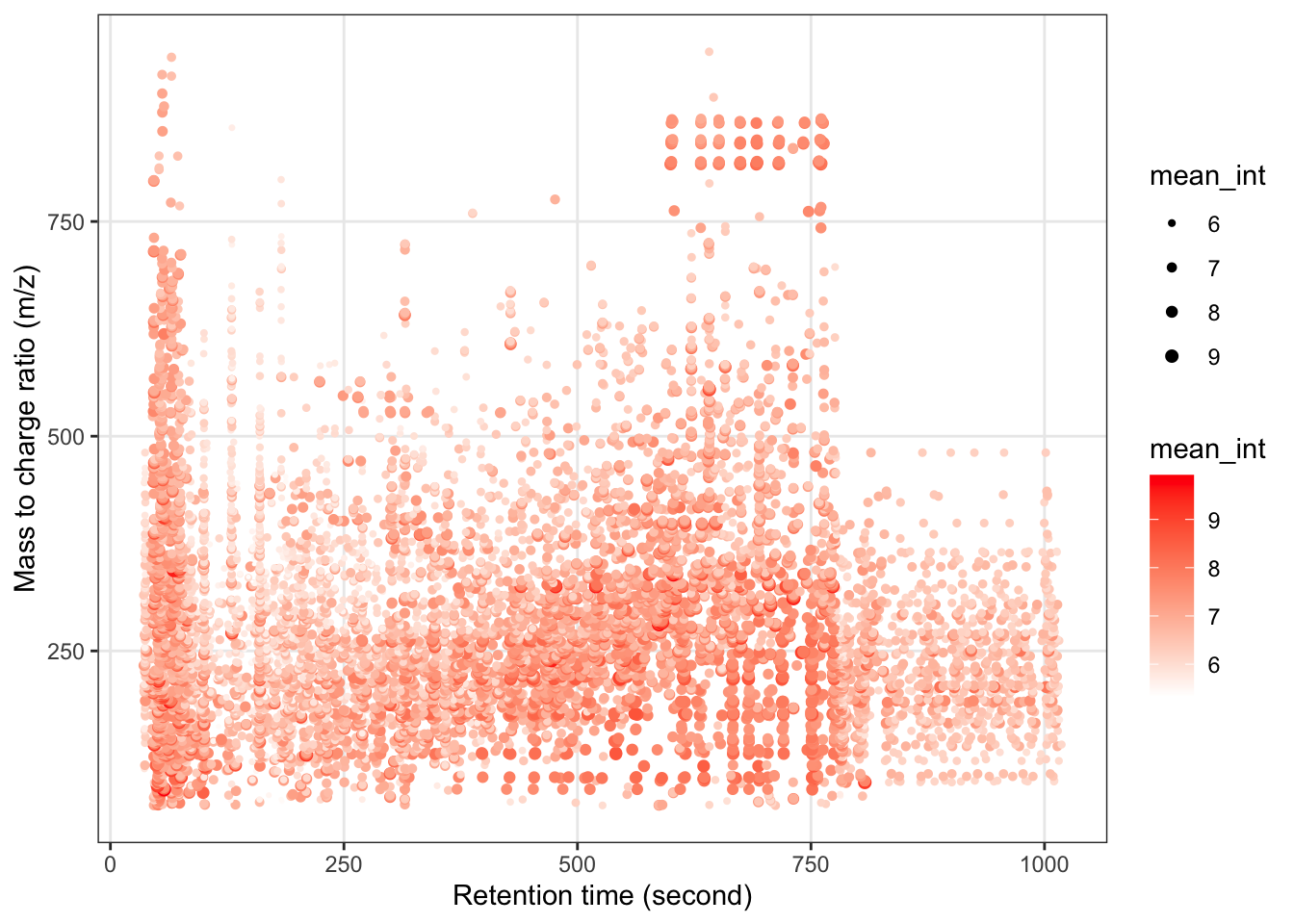
Next, we can get the peak distributation plot of negative mode.
object_neg %>%
`+`(1) %>%
log(10) %>%
show_mz_rt_plot() +
scale_size_continuous(range = c(0.01, 2))
We can explore the missing values in negitive mode data.
get_mv_number(object = object_neg)
#> [1] 748253
748,253 mvs in total.
get_mv_number(object = object_neg, by = "sample") %>%
head()
#> sample_06 sample_103 sample_11 sample_112 sample_117 sample_12
#> 3029 2766 3298 3100 2912 3053
Missing value number in each sample.
get_mv_number(object = object_neg, by = "variable") %>%
head()
#> M70T712_NEG M70T527_NEG M70T587_NEG M70T47_NEG M71T587_NEG M71T641_NEG
#> 16 137 2 146 41 19
Missing value number in each variable.
We can use the figure to show the missing value information.
show_missing_values(object = object_neg, show_column_names = FALSE, percentage = TRUE)
Show the mvs in samples.
show_sample_missing_values(object = object_neg, percentage = TRUE)

Show the mvs in variables.
show_variable_missing_values(object = object_neg,
percentage = TRUE,
show_x_text = FALSE,
show_x_ticks = FALSE) +
scale_size_continuous(range = c(0.01, 1))
Conclusion
So from those exploration, we have a brief summary of our data. Next, we will use masscleaner pacakge to do the data cleaning of data.
Session information
sessionInfo()
#> R version 4.4.1 (2024-06-14)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS 15.0
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> time zone: Asia/Singapore
#> tzcode source: internal
#>
#> attached base packages:
#> [1] grid stats4 stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
#> [4] purrr_1.0.2 readr_2.1.5 tibble_3.2.1
#> [7] tidyverse_2.0.0 metid_1.2.33 metpath_1.0.8
#> [10] ComplexHeatmap_2.20.0 mixOmics_6.28.0 lattice_0.22-6
#> [13] MASS_7.3-61 massstat_1.0.6 tidyr_1.3.1
#> [16] ggfortify_0.4.17 massqc_1.0.7 masscleaner_1.0.12
#> [19] MSnbase_2.30.1 ProtGenerics_1.36.0 S4Vectors_0.42.1
#> [22] Biobase_2.64.0 BiocGenerics_0.50.0 mzR_2.38.0
#> [25] Rcpp_1.0.13 xcms_4.2.3 BiocParallel_1.38.0
#> [28] massprocesser_1.0.10 ggplot2_3.5.1 dplyr_1.1.4
#> [31] magrittr_2.0.3 masstools_1.0.13 massdataset_1.0.34
#> [34] tidymass_1.0.9
#>
#> loaded via a namespace (and not attached):
#> [1] fs_1.6.4 matrixStats_1.3.0
#> [3] bitops_1.0-8 fit.models_0.64
#> [5] httr_1.4.7 RColorBrewer_1.1-3
#> [7] doParallel_1.0.17 tools_4.4.1
#> [9] doRNG_1.8.6 backports_1.5.0
#> [11] utf8_1.2.4 R6_2.5.1
#> [13] lazyeval_0.2.2 GetoptLong_1.0.5
#> [15] withr_3.0.1 prettyunits_1.2.0
#> [17] gridExtra_2.3 preprocessCore_1.66.0
#> [19] cli_3.6.3 Cairo_1.6-2
#> [21] fastDummies_1.7.4 labeling_0.4.3
#> [23] sass_0.4.9 mvtnorm_1.3-1
#> [25] robustbase_0.99-4 randomForest_4.7-1.1
#> [27] proxy_0.4-27 pbapply_1.7-2
#> [29] foreign_0.8-87 rrcov_1.7-6
#> [31] MetaboCoreUtils_1.12.0 parallelly_1.38.0
#> [33] itertools_0.1-3 limma_3.60.4
#> [35] readxl_1.4.3 rstudioapi_0.16.0
#> [37] impute_1.78.0 generics_0.1.3
#> [39] shape_1.4.6.1 vroom_1.6.5
#> [41] zip_2.3.1 Matrix_1.7-0
#> [43] MALDIquant_1.22.3 fansi_1.0.6
#> [45] abind_1.4-5 lifecycle_1.0.4
#> [47] yaml_2.3.10 SummarizedExperiment_1.34.0
#> [49] SparseArray_1.4.8 crayon_1.5.3
#> [51] PSMatch_1.8.0 KEGGREST_1.44.1
#> [53] magick_2.8.4 pillar_1.9.0
#> [55] knitr_1.48 GenomicRanges_1.56.1
#> [57] rjson_0.2.22 corpcor_1.6.10
#> [59] codetools_0.2-20 glue_1.7.0
#> [61] pcaMethods_1.96.0 data.table_1.16.0
#> [63] remotes_2.5.0 MultiAssayExperiment_1.30.3
#> [65] vctrs_0.6.5 png_0.1-8
#> [67] cellranger_1.1.0 gtable_0.3.5
#> [69] cachem_1.1.0 xfun_0.47
#> [71] openxlsx_4.2.7 S4Arrays_1.4.1
#> [73] tidygraph_1.3.1 pcaPP_2.0-5
#> [75] ncdf4_1.23 iterators_1.0.14
#> [77] statmod_1.5.0 bit64_4.0.5
#> [79] robust_0.7-5 progress_1.2.3
#> [81] GenomeInfoDb_1.40.1 rprojroot_2.0.4
#> [83] bslib_0.8.0 affyio_1.74.0
#> [85] rpart_4.1.23 colorspace_2.1-1
#> [87] DBI_1.2.3 Hmisc_5.1-3
#> [89] nnet_7.3-19 tidyselect_1.2.1
#> [91] bit_4.0.5 compiler_4.4.1
#> [93] MassSpecWavelet_1.70.0 htmlTable_2.4.3
#> [95] DelayedArray_0.30.1 plotly_4.10.4
#> [97] bookdown_0.40 checkmate_2.3.2
#> [99] scales_1.3.0 DEoptimR_1.1-3
#> [101] affy_1.82.0 digest_0.6.37
#> [103] rmarkdown_2.28 XVector_0.44.0
#> [105] htmltools_0.5.8.1 pkgconfig_2.0.3
#> [107] base64enc_0.1-3 MatrixGenerics_1.16.0
#> [109] highr_0.11 fastmap_1.2.0
#> [111] rlang_1.1.4 GlobalOptions_0.1.2
#> [113] htmlwidgets_1.6.4 UCSC.utils_1.0.0
#> [115] farver_2.1.2 jquerylib_0.1.4
#> [117] jsonlite_1.8.8 MsExperiment_1.6.0
#> [119] mzID_1.42.0 RCurl_1.98-1.16
#> [121] Formula_1.2-5 GenomeInfoDbData_1.2.12
#> [123] patchwork_1.2.0 munsell_0.5.1
#> [125] viridis_0.6.5 MsCoreUtils_1.16.1
#> [127] vsn_3.72.0 furrr_0.3.1
#> [129] stringi_1.8.4 ggraph_2.2.1
#> [131] zlibbioc_1.50.0 plyr_1.8.9
#> [133] parallel_4.4.1 listenv_0.9.1
#> [135] ggrepel_0.9.5 Biostrings_2.72.1
#> [137] MsFeatures_1.12.0 graphlayouts_1.1.1
#> [139] hms_1.1.3 Spectra_1.14.1
#> [141] circlize_0.4.16 igraph_2.0.3
#> [143] QFeatures_1.14.2 rngtools_1.5.2
#> [145] reshape2_1.4.4 XML_3.99-0.17
#> [147] evaluate_0.24.0 blogdown_1.19
#> [149] BiocManager_1.30.25 tzdb_0.4.0
#> [151] foreach_1.5.2 missForest_1.5
#> [153] tweenr_2.0.3 polyclip_1.10-7
#> [155] future_1.34.0 clue_0.3-65
#> [157] ggforce_0.4.2 AnnotationFilter_1.28.0
#> [159] e1071_1.7-14 RSpectra_0.16-2
#> [161] ggcorrplot_0.1.4.1 viridisLite_0.4.2
#> [163] class_7.3-22 rARPACK_0.11-0
#> [165] memoise_2.0.1 ellipse_0.5.0
#> [167] IRanges_2.38.1 cluster_2.1.6
#> [169] timechange_0.3.0 globals_0.16.3
#> [171] here_1.0.1