Here, you can learn how to create mass_dataset class object using tidymass.
Data preparation
The massdataset class object can be used to store the untargeted metabolomics data.
Let’s first prepare the data objects according to the attached figure for each file.
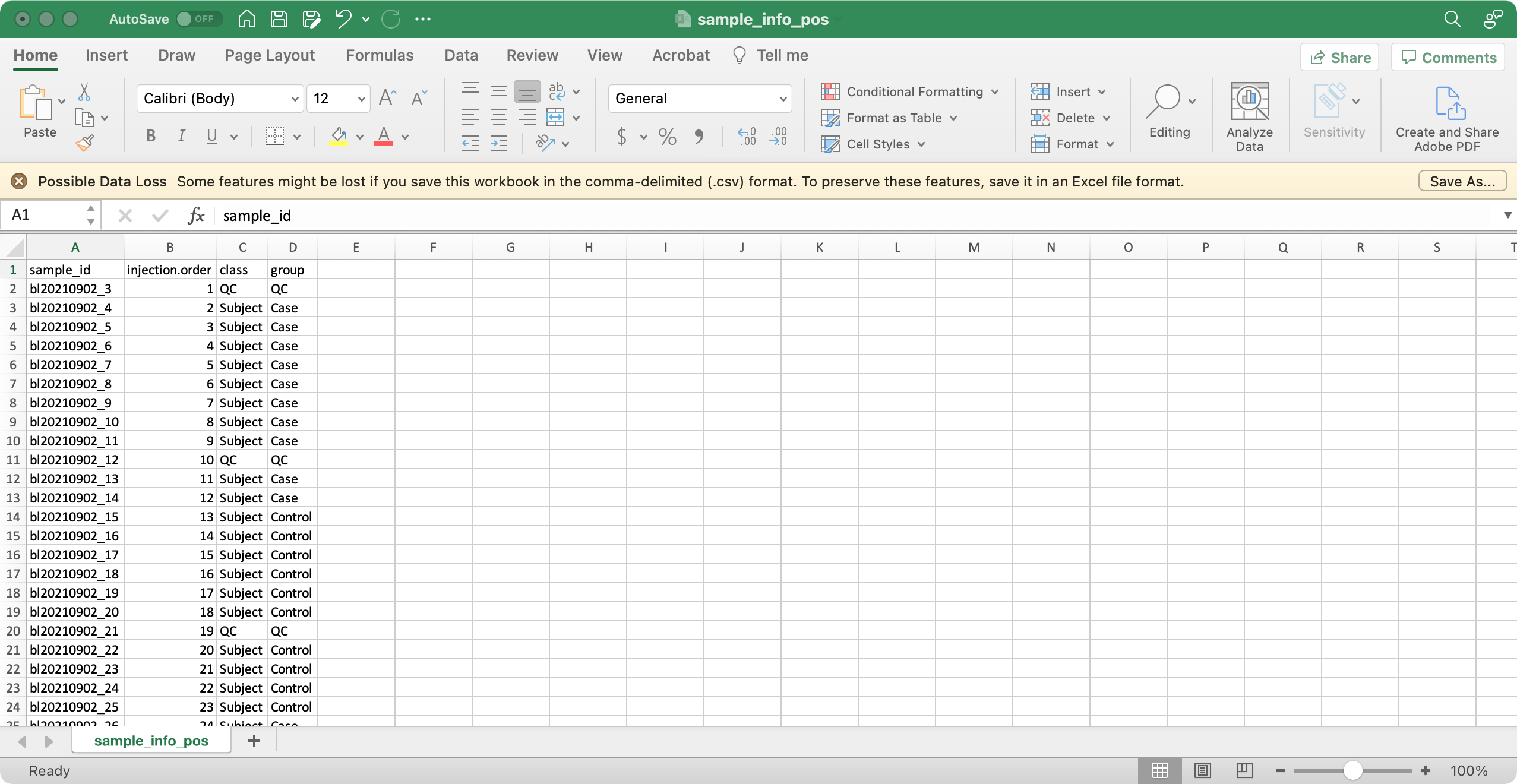
1. sample_info (required)
The columns sample_id (sample ID), injection.order (injection order of samples), class (Blank, QC, Subject, etc), group (case, control, etc) are required.
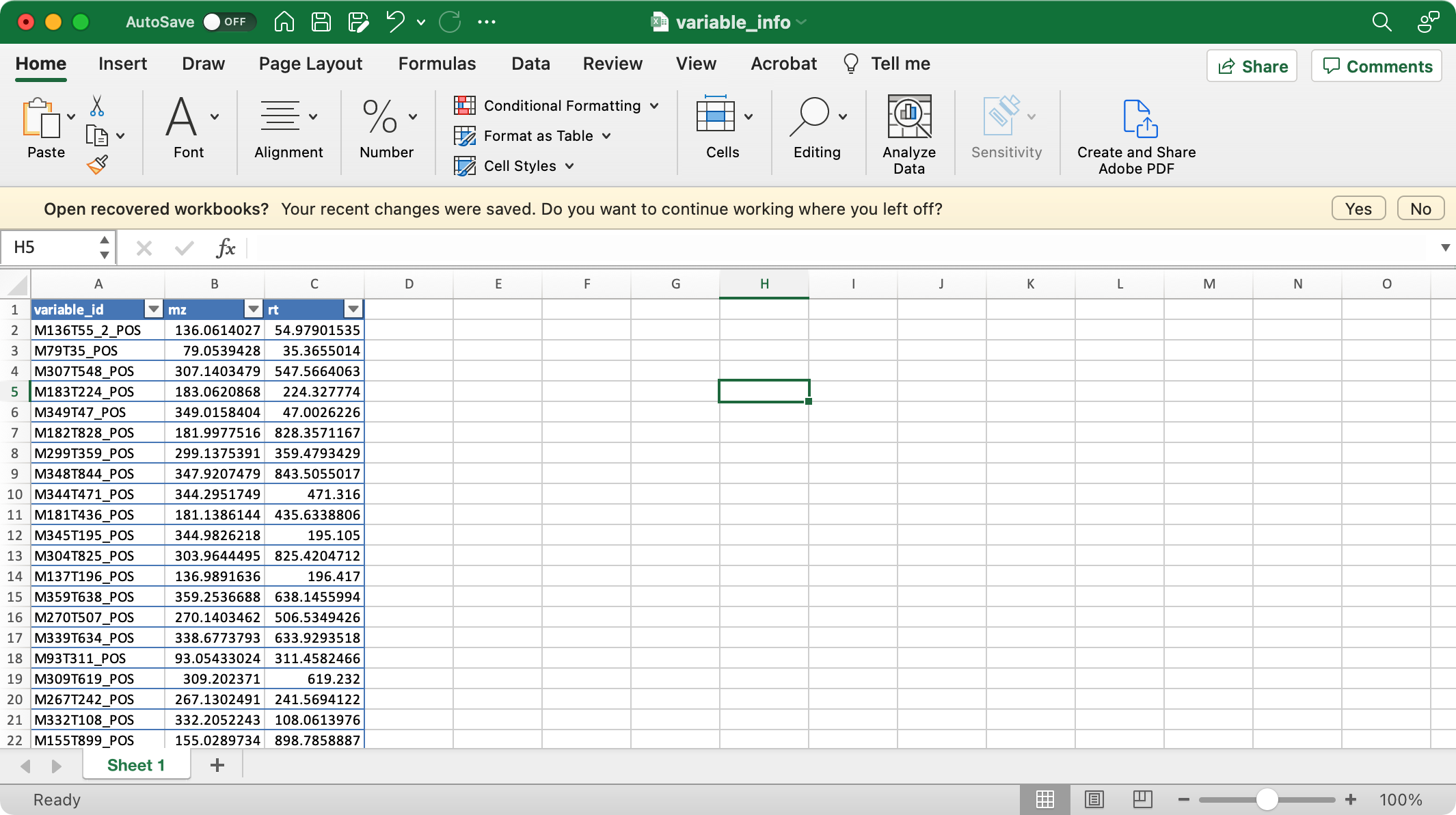
2. variable_info (required)
The columns variable_id (variable ID), mz (mass to charge ratio), rt (retention time, unit is second) are required.
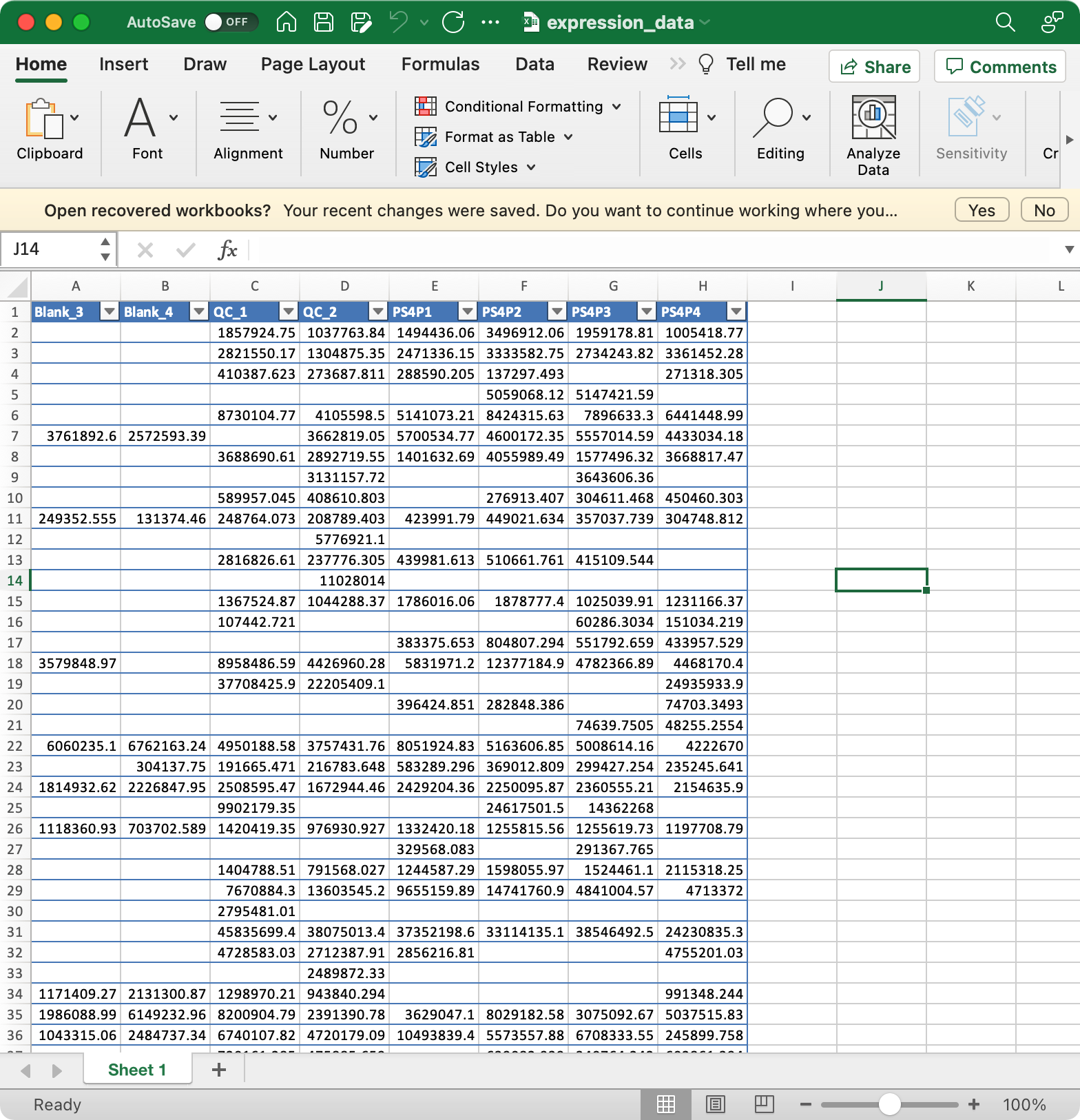
3. expression_data (required)
Columns are samples are rows are features (variables).
The column names of expression_data should be completely same with sample_id in
sample_info, and the row names of expression_data should be completely same with variable_id invariable_info.
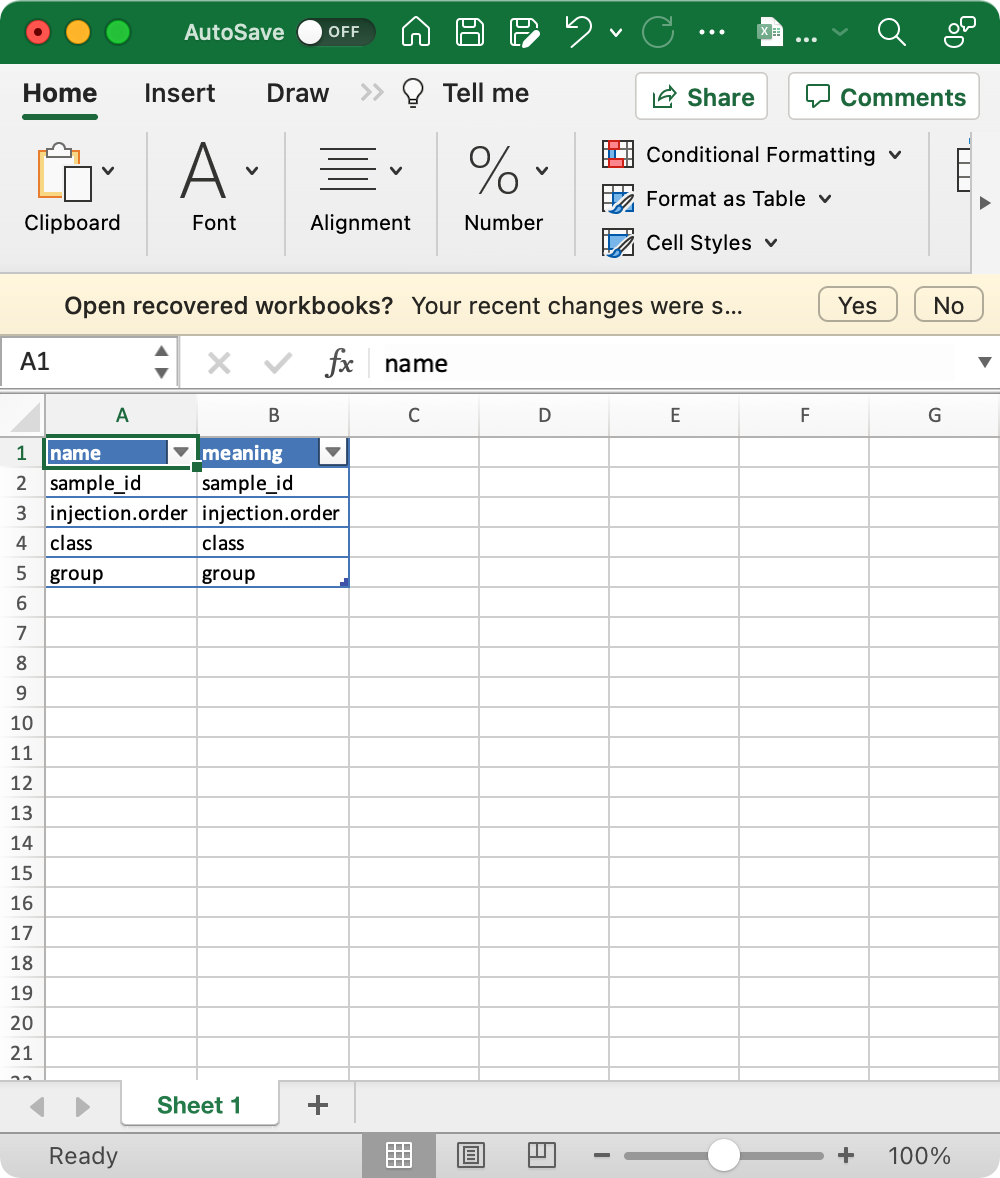
4. sample_info_note (optional)
This is the metadata for sample_info.
5. variable_info_note (optional)
This is the metadata for variable_info.
Download demo data
Here we use the demo data from masssprocesser package. The demo data can be downloaded here.
Download this data and uncompress it. And then set the path where you put the folder as working directory.
Then prepare data.
library(tidyverse)
#> ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.4 ✔ readr 2.1.5
#> ✔ forcats 1.0.0 ✔ stringr 1.5.1
#> ✔ ggplot2 3.5.1 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
peak_table_pos = readr::read_csv("feature_table/Peak_table_pos.csv")
#> Rows: 1612 Columns: 39
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (1): variable_id
#> dbl (38): mz, rt, bl20210902_10, bl20210902_11, bl20210902_13, bl20210902_14...
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
peak_table_neg = readr::read_csv("feature_table/Peak_table_neg.csv")
#> Rows: 5486 Columns: 39
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (1): variable_id
#> dbl (38): mz, rt, X20210902_neg04, X20210902_neg05, X20210902_neg06, X202109...
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
sample_info_pos = readr::read_csv("feature_table/sample_info_pos.csv")
#> Rows: 36 Columns: 4
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (3): sample_id, class, group
#> dbl (1): injection.order
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
sample_info_neg = readr::read_csv("feature_table/sample_info_neg.csv")
#> Rows: 36 Columns: 4
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (3): sample_id, class, group
#> dbl (1): injection.order
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Variable information and expression data are in the peak table. Let’s separate them.
expression_data_pos =
peak_table_pos %>%
dplyr::select(-c(variable_id:rt)) %>%
as.data.frame()
variable_info_pos =
peak_table_pos %>%
dplyr::select(variable_id:rt) %>%
as.data.frame()
rownames(expression_data_pos) = variable_info_pos$variable_id
expression_data_neg =
peak_table_neg %>%
dplyr::select(-c(variable_id:rt)) %>%
as.data.frame()
variable_info_neg =
peak_table_neg %>%
dplyr::select(variable_id:rt) %>%
as.data.frame()
rownames(expression_data_neg) = variable_info_neg$variable_id
colnames(expression_data_pos) == sample_info_pos$sample_id
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
colnames(expression_data_neg) == sample_info_neg$sample_id
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
The orders of sample_id in sample_info and column names of expression_data are different.
expression_data_pos =
expression_data_pos[,sample_info_pos$sample_id]
expression_data_neg =
expression_data_neg[,sample_info_neg$sample_id]
colnames(expression_data_pos) == sample_info_pos$sample_id
#> [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [16] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [31] TRUE TRUE TRUE TRUE TRUE TRUE
colnames(expression_data_neg) == sample_info_neg$sample_id
#> [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [16] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [31] TRUE TRUE TRUE TRUE TRUE TRUE
Create mass_data class object
Then we can create mass_data class object using create_mass_dataset() function.
library(massdataset)
#> massdataset 1.0.34 (2024-09-10 06:51:30.673357)
#>
#> Attaching package: 'massdataset'
#> The following object is masked from 'package:stats':
#>
#> filter
object_pos =
create_mass_dataset(
expression_data = expression_data_pos,
sample_info = sample_info_pos,
variable_info = variable_info_pos
)
object_pos
#> --------------------
#> massdataset version: 1.0.34
#> --------------------
#> 1.expression_data:[ 1612 x 36 data.frame]
#> 2.sample_info:[ 36 x 4 data.frame]
#> 36 samples:bl20210902_3 bl20210902_4 bl20210902_5 ... bl20210902_37 bl20210902_38
#> 3.variable_info:[ 1612 x 3 data.frame]
#> 1612 variables:M86T44_POS M90T638_POS M91T631_POS ... M1197T265_POS M1198T265_POS
#> 4.sample_info_note:[ 4 x 2 data.frame]
#> 5.variable_info_note:[ 3 x 2 data.frame]
#> 6.ms2_data:[ 0 variables x 0 MS2 spectra]
#> --------------------
#> Processing information
#> 1 processings in total
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2024-09-25 17:21:43
Then negative mode.
object_neg =
create_mass_dataset(
expression_data = expression_data_neg,
sample_info = sample_info_neg,
variable_info = variable_info_neg
)
object_neg
#> --------------------
#> massdataset version: 1.0.34
#> --------------------
#> 1.expression_data:[ 5486 x 36 data.frame]
#> 2.sample_info:[ 36 x 4 data.frame]
#> 36 samples:X20210902_neg03 X20210902_neg04 X20210902_neg05 ... X20210902_neg37 X20210902_neg38
#> 3.variable_info:[ 5486 x 3 data.frame]
#> 5486 variables:M74T229_NEG M88T115_NEG M100T631_NEG ... M1199T22_NEG M1199T180_NEG
#> 4.sample_info_note:[ 4 x 2 data.frame]
#> 5.variable_info_note:[ 3 x 2 data.frame]
#> 6.ms2_data:[ 0 variables x 0 MS2 spectra]
#> --------------------
#> Processing information
#> 1 processings in total
#> create_mass_dataset ----------
#> Package Function.used Time
#> 1 massdataset create_mass_dataset() 2024-09-25 17:21:43
Then save them for next analysis.
save(object_pos, file = "feature_table/object_pos")
save(object_neg, file = "feature_table/object_neg")
Export mass_dataset class object to csv for xlsx
export_mass_dataset(object = object_pos,
file_type = "xlsx",
path = "feature_table/demo_data_pos")
Then all the data will be in the feature_table/demo_data_pos folder.
Session information
sessionInfo()
#> R version 4.4.1 (2024-06-14)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS 15.0
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> time zone: Asia/Singapore
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] magrittr_2.0.3 masstools_1.0.13 massdataset_1.0.34 lubridate_1.9.3
#> [5] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
#> [9] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1
#> [13] tidyverse_2.0.0
#>
#> loaded via a namespace (and not attached):
#> [1] bitops_1.0-8 pbapply_1.7-2
#> [3] remotes_2.5.0 rlang_1.1.4
#> [5] clue_0.3-65 GetoptLong_1.0.5
#> [7] matrixStats_1.3.0 compiler_4.4.1
#> [9] reshape2_1.4.4 png_0.1-8
#> [11] vctrs_0.6.5 ProtGenerics_1.36.0
#> [13] pkgconfig_2.0.3 shape_1.4.6.1
#> [15] crayon_1.5.3 fastmap_1.2.0
#> [17] XVector_0.44.0 utf8_1.2.4
#> [19] rmarkdown_2.28 tzdb_0.4.0
#> [21] preprocessCore_1.66.0 UCSC.utils_1.0.0
#> [23] bit_4.0.5 xfun_0.47
#> [25] MultiAssayExperiment_1.30.3 zlibbioc_1.50.0
#> [27] cachem_1.1.0 GenomeInfoDb_1.40.1
#> [29] jsonlite_1.8.8 DelayedArray_0.30.1
#> [31] BiocParallel_1.38.0 parallel_4.4.1
#> [33] cluster_2.1.6 R6_2.5.1
#> [35] bslib_0.8.0 stringi_1.8.4
#> [37] RColorBrewer_1.1-3 limma_3.60.4
#> [39] GenomicRanges_1.56.1 jquerylib_0.1.4
#> [41] Rcpp_1.0.13 bookdown_0.40
#> [43] SummarizedExperiment_1.34.0 iterators_1.0.14
#> [45] knitr_1.48 IRanges_2.38.1
#> [47] igraph_2.0.3 Matrix_1.7-0
#> [49] timechange_0.3.0 tidyselect_1.2.1
#> [51] abind_1.4-5 rstudioapi_0.16.0
#> [53] yaml_2.3.10 affy_1.82.0
#> [55] doParallel_1.0.17 codetools_0.2-20
#> [57] blogdown_1.19 plyr_1.8.9
#> [59] lattice_0.22-6 Biobase_2.64.0
#> [61] withr_3.0.1 evaluate_0.24.0
#> [63] zip_2.3.1 circlize_0.4.16
#> [65] BiocManager_1.30.25 affyio_1.74.0
#> [67] pillar_1.9.0 MatrixGenerics_1.16.0
#> [69] foreach_1.5.2 stats4_4.4.1
#> [71] MALDIquant_1.22.3 MSnbase_2.30.1
#> [73] ncdf4_1.23 generics_0.1.3
#> [75] RCurl_1.98-1.16 vroom_1.6.5
#> [77] rprojroot_2.0.4 S4Vectors_0.42.1
#> [79] hms_1.1.3 munsell_0.5.1
#> [81] scales_1.3.0 glue_1.7.0
#> [83] lazyeval_0.2.2 tools_4.4.1
#> [85] mzID_1.42.0 vsn_3.72.0
#> [87] QFeatures_1.14.2 mzR_2.38.0
#> [89] openxlsx_4.2.7 XML_3.99-0.17
#> [91] grid_4.4.1 impute_1.78.0
#> [93] MsCoreUtils_1.16.1 colorspace_2.1-1
#> [95] GenomeInfoDbData_1.2.12 PSMatch_1.8.0
#> [97] cli_3.6.3 fansi_1.0.6
#> [99] S4Arrays_1.4.1 ComplexHeatmap_2.20.0
#> [101] AnnotationFilter_1.28.0 pcaMethods_1.96.0
#> [103] gtable_0.3.5 sass_0.4.9
#> [105] digest_0.6.37 BiocGenerics_0.50.0
#> [107] SparseArray_1.4.8 rjson_0.2.22
#> [109] htmltools_0.5.8.1 lifecycle_1.0.4
#> [111] httr_1.4.7 here_1.0.1
#> [113] statmod_1.5.0 GlobalOptions_0.1.2
#> [115] bit64_4.0.5 MASS_7.3-61